この記事は ZOZO Advent Calendar 2021 の13日目の記事です。
AWSのCloudWatch Alarmを利用していて、欠落データが含まれるときのアラーム状態の評価について知らなかったので実際に試しながら学びました。
参考資料
アラームについて
CloudWatch Alarmにおいてアラームの状態はOK、ALARM、INSUFFICIENT_DATAの3種類あります。ざっくり言うと順に正常、異常、データ不足という分類になります(正確な定義はドキュメントを参照ください)。アラームの評価は、直近のデータポイントのN個中M個が閾値を超える場合にALARM状態へ遷移するという考え方です。データポイントはユーザーが設定した期間でメトリクスが評価され作成されるものです。
ここで欠落データの話をすると、サーバーがダウンした、エラー時のみにデータを送信するなど何らかの理由によりCloudWatchメトリクスにデータが送られない場合があり、データポイントを作成できないのでこれを欠落データとか欠落データポイントとか呼んでいるようです。欠落データがそのまま扱われると都合が悪い場面があって、サーバーが落ちているから欠落しているので異常扱いにしたい、正常だから欠落しているので正常扱いにしたいなどのニーズに応えられるよう欠落データをどのように扱うかユーザーは選択できます。
こちらに欠落データの扱い方を示します(ドキュメントから引用)。
| 名称 | 意味 |
|---|---|
| notBreaching | 欠落データポイントは「良好」とされ、しきい値内として扱われます。 |
| breaching | 欠落データポイントは「不良」とされ、しきい値超過として扱われます。 |
| ignore | 現在のアラーム状態が維持されます。 |
| missing | (デフォルト値)アラーム評価範囲内のすべてのデータポイントがない場合、アラームは INSUFFICIENT_DATA に移行します。 |
想定する状況
システムを運用する上で欠落データが発生する状況はいくつか考えられますが、今回は実際に遭遇した状況を単純化してアラームがどう評価されるか見ていこうと思います。
- 例)ALBのHTTPCode_Target_5XX_Countメトリクスを対象とするアラーム
- https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/application/load-balancer-cloudwatch-metrics.html
- このメトリクスは5xxのレスポンスが1件でも発生するとレポートされる(0件だとレポートされないため0という値にはならないのがポイント)
- 普段は正常稼動していて、デプロイ後にエラーが頻発し始めた、急にアクセス数が増えてバックエンドが応答できなくなった等でALARM状態としたい
遭遇した状況は、あるデータポイントで閾値を越え、その後データが欠落した状態で数分経過し、再び複数回(但しN個中M個のM個までではない)閾値を越えたときにALARM状態に遷移というものです。このときに感じたことは欠落データについて不勉強であったこともあり、ALARM状態に遷移するほど閾値を越えてないはずなのになぜALARM状態になったのかということでした。
調査用環境
今回の調査は欠落データの扱い方を変えながら閾値を越えるデータポイントを発生させて、アラームがどのように評価されるかを見ることにしました。以下の図に示す環境を用意しました。
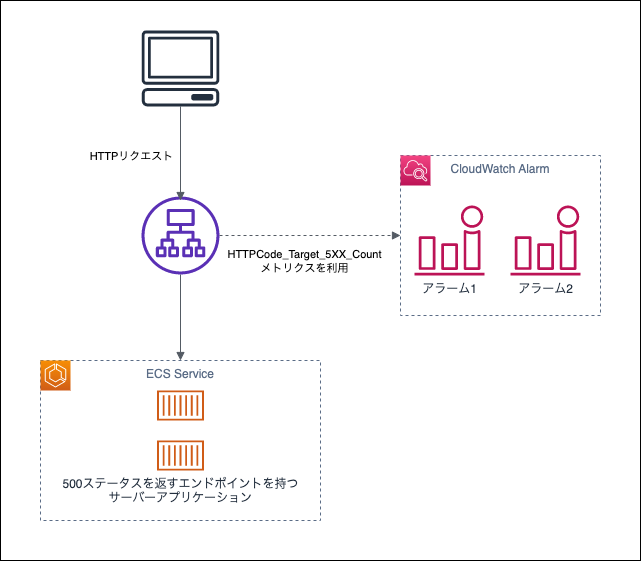
アラームを2つ用意してそれぞれ以下の条件としました。
- アラーム1: HTTPCode_Target_5XX_Countが1分で5件発生することを閾値として、データポイントの3個中3個が閾値を超えるとALARM状態になる
- アラーム2: HTTPCode_Target_5XX_Countが1分で5件発生することを閾値として、データポイントの5個中3個が閾値を超えるとALARM状態になる
アラーム1はドキュメントに例示されているものに寄せていて(3個中3個が閾値を超えると、の部分。1分でという期間については不明だった)、例のような評価がなされるのか確認する狙いがあります。また、アラーム2はN個中M個の部分を異なる値にしてアラーム1の場合と評価が変わるかを確認する狙いがあります。
HTTPCode_Target_5XX_Countの数を増やすために、サーバーアプリケーションに必ず500コードを返すエンドポイントを設置しここに向けていくつかのパターンでリクエストを行いました。
調査1: 1分間エラーリクエスト実行→2分間なし→2分間エラーリクエスト実行
| 欠落データの扱い | アラーム1の状態変化 | アラーム2の状態変化 |
|---|---|---|
| notBreaching | OK -> ALARM->OK | OK -> ALARM->OK |
| breaching | ALARM | ALARM |
| ignore | INSUFFICIENT_DATA -> ALARM | INSUFFICIENT_DATA -> ALARM |
| missing | INSUFFICIENT_DATA -> ALARM->INSUFFICIENT_DATA | INSUFFICIENT_DATA -> ALARM->INSUFFICIENT_DATA |
この表の状態変化は、エラーリクエスト実行前の状態を左側に示してリクエスト中もしくはリクエスト後に状態が変化すれば矢印の右側に次の状態を示しています。
まず、アラーム1に関して見ていきます。notBreachingでは3個中3個閾値を越えるという条件なので最後の3分間を見ると3個中2個なので状態はOKのままかなと予想していました。しかし予想とは異なりALARMに変化しました。少し話がそれますが、CloudWatch Alarmのマネージドコンソールには「履歴」というメニューがありアラームの状態変化に関するデータを見ることができます(APIだとDescribeAlarmHistory)。得られるデータはJSON形式なのですが historyData.newState.stateReasonData という階層のrecentDatapoints, evaluatedDatapointsを見てどのデータポイントが利用されたのか判断しました。notBreachingのときのrecentDatapointsは [6, null, null, 6, 6] で、本来は3つのデータポイントを見ておけばいいけど欠落しているのでより多く(遡って)データポイントを取得して評価しているのが分かります。これについてはドキュメントで以下のように記載されています。
アラームが状態を変更するかどうかを評価するたびに、CloudWatch は [Evaluation Periods (評価期間)] に指定されている数よりも多くのデータポイントを取得しようとします。取得を試みるデータポイントの正確な数は、アラーム期間の長さと、基づいているメトリクスが標準解像度か高解像度かによって異なります。取得を試みるデータポイントのタイムフレームは評価範囲です。
CloudWatch がこれらのデータポイントを取得すると、次の処理が実行されます。
評価範囲内のデータポイントが欠落していない場合、CloudWatch は収集された最新のデータポイントに基づいてアラームを評価します。評価されるデータポイントの数は、アラームの [Evaluation Periods (評価期間) ] と同じです。評価範囲内のよりさかのぼった時点からの余分なデータポイントは必要なく、無視されます。
評価範囲内のデータポイントの一部が欠落しているが、評価範囲から正常に取得された既存のデータポイントの合計数がアラームの [Evaluation Periods (評価期間) ] 以上である場合、CloudWatch は、最新の正常に取得された最新のデータポイントに基づいたアラームの状態を評価します (評価範囲内のよりさかのぼった時点からの必要な追加データポイントを含む)。この場合、欠落データを処理する方法に設定した値は不要であり、無視されます。
評価範囲のデータポイントの一部が欠落しており、取得された既存のデータポイントの数がアラームの [Evaluation Periods (評価期間)] の数を下回る場合、CloudWatch によって、欠落データ部分に欠落データの処理方法に指定された結果が入力され、アラームが評価されます。ただし、評価範囲内のすべての実際のデータポイントが評価に含まれます。CloudWatch は、欠落データポイントの使用を最小限に抑えます。
今回のパターンはおそらく「評価範囲内のデータポイントの一部が欠落しているが、評価範囲から正常に取得された既存のデータポイントの合計数がアラームの [Evaluation Periods (評価期間) ] 以上である場合」に相当するので、欠落していない3つのデータポイントを評価に利用して3つとも閾値を越えているのでALARMになったと考えられます。ignoreも同様にALARMに変わりましたが、リクエストを実行し終えた後もALARMから変わることはありませんでした。リクエストが無くなり欠落データのみになったことで、先ほどの引用の中の「評価範囲のデータポイントの一部が欠落しており、取得された既存のデータポイントの数がアラームの [Evaluation Periods (評価期間)] の数を下回る場合」に相当し現在のアラーム状態が維持されるという扱いで評価されたのでしょう。
missingは少し異なり、recentDatapointsは [6] でevaluatedDatapointsは6を記録したデータポイントと値のないデータポイント2つとなっていました。これはドキュメント内の「早期アラーム状態」に当たると思われます。breachingについては設定してまもなくALARM状態になり、一連のリクエストを実行したときにはALARMからの変化はありませんでした。
アラーム2はアラーム1と全て同じ評価でしたが、リクエストを実行し終えた後にALARMから別の状態に遷移するタイミングがアラーム1よりも少し遅れていました。これはアラーム1が3データポイントを評価するのに対してアラーム2は5データポイントを評価するためだと思われます。
ここからはnotBreachingに注目して見ていきます。(他の欠落データの扱い方は調査1で見られた現象とずっと同じでした)
調査2: 1分間エラーリクエスト実行→3分間なし→2分間エラーリクエスト実行
| 欠落データの扱い | アラーム1の状態変化 | アラーム2の状態変化 |
|---|---|---|
| notBreaching | OK -> ALARM->OK | OK -> ALARM->OK |
閾値を越えるデータポイントの間隔を空ければOKのままになるのではないかと予想してのこのパターンです。しかし、状態の遷移だけ見ると調査1と同じ結果になりました。recentDatapointsはアラーム1・2両者とも [6, null, null, null, 6, 6] でした。ALARMからOKになる間隔を調べると、アラーム1は調査1: 4分、調査2: 3分、アラーム2は調査1: 6分、調査2: 5分となっており、合間により多く欠落データが挟まると最初の閾値を越えるデータポイントが評価範囲に入らなくなる時間が早まることに気付きました。
これを踏まえて次はもう少し間隔を空けてみます。
調査3: 1分間エラーリクエスト実行→6分間なし→2分間エラーリクエスト実行
| 欠落データの扱い | アラーム1の状態変化 | アラーム2の状態変化 |
|---|---|---|
| notBreaching | OK | OK -> ALARM->OK |
閾値を越えるデータポイントの間隔をもう3分広げればアラーム1はALARMにならないのではないかと思い検証しました。結果は以下のキャプチャのようにOKのままでした(状態遷移しないので履歴データが取れない)。データポイントの時刻が分かりづらいですが順に18:32、18:39、18:40となっています。おそらく8個のデータポイント(18:32〜18:39、18:33〜18:40)が評価範囲となっており、「評価範囲のデータポイントの一部が欠落しており、取得された既存のデータポイントの数がアラームの [Evaluation Periods (評価期間)] の数を下回る場合」だったため閾値を越えるデータポイントは2個だけど他は正常と見なされて評価された結果だと考えられます。
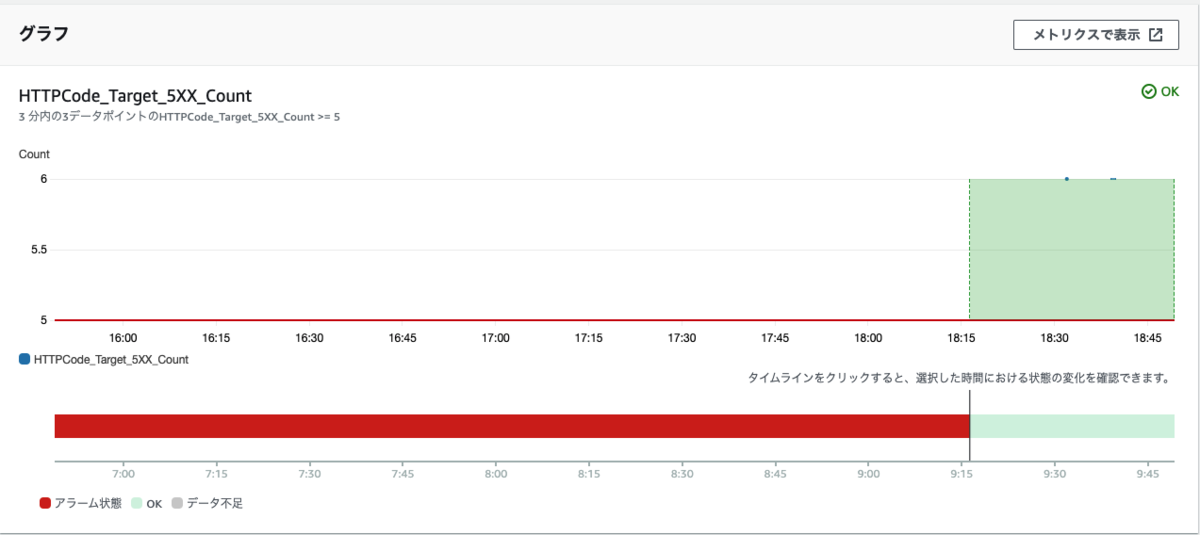
アラーム2ではOKからALARMに変わりました。recentDatapointsは [6, null, null, null, null, null, null, 6, 6] で最初の1分間のデータポイントが含まれていました。
おわりに
今回いろいろなパターンのリクエストでアラームの状態を見てみましたが、欠落データがある場合は設定したデータポイント数よりも遡ってデータポイントを取得しアラームが評価されると分かりました。正確にどこまで遡るかは細かな仕様が書かれていませんので不明ですが、一見して閾値を越えた回数が少ないのにALARM状態になった場合でもこういうことは起き得るというのを知っていればアラームが変だとか疑わずに本来やるべき対応に集中できそうです。